Presence AI
Problem
The conversational space is mostly saturated by text-based interactions. How do we elevate human and AI conversation? (eg. format or cadence)
Proposal
Multimodal consumer-facing realtime digital avatar application (generative video + audio)
My Contributions
As the founding designer on a team of mostly engineers, I was responsible for the design of a 0-1 product: interactions, design system, and user interface. I also supported the team in research, analytics, and product strategies.
Phase 1: Roulette interaction
67% user start call (+13% from beginning) but only 0.3% next day retention rate.
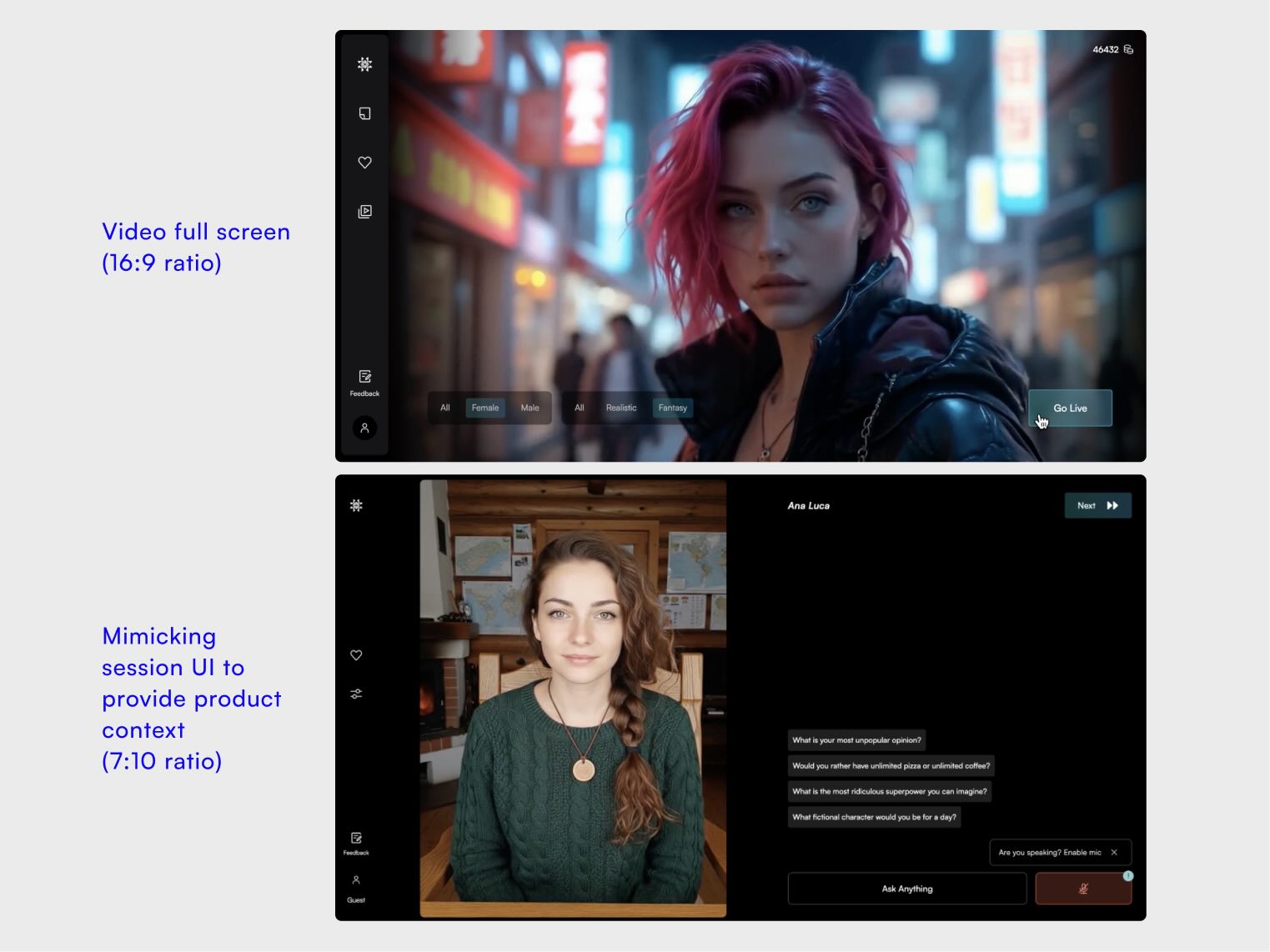
Roulette interaction (randomized avatars)
Phase 2: Customization (user create)
Only 18.97% desktop user complete the creation flow vs. 8% mobile BUT first time seeing organic retention (eg. 200 return users in one day)
Creation (letting user create)
Building for speed
I spun up a flexible design system that allowed engineers to build efficiently and push to production every 2 weeks to get real user feedback and learn usage and opportunity through data
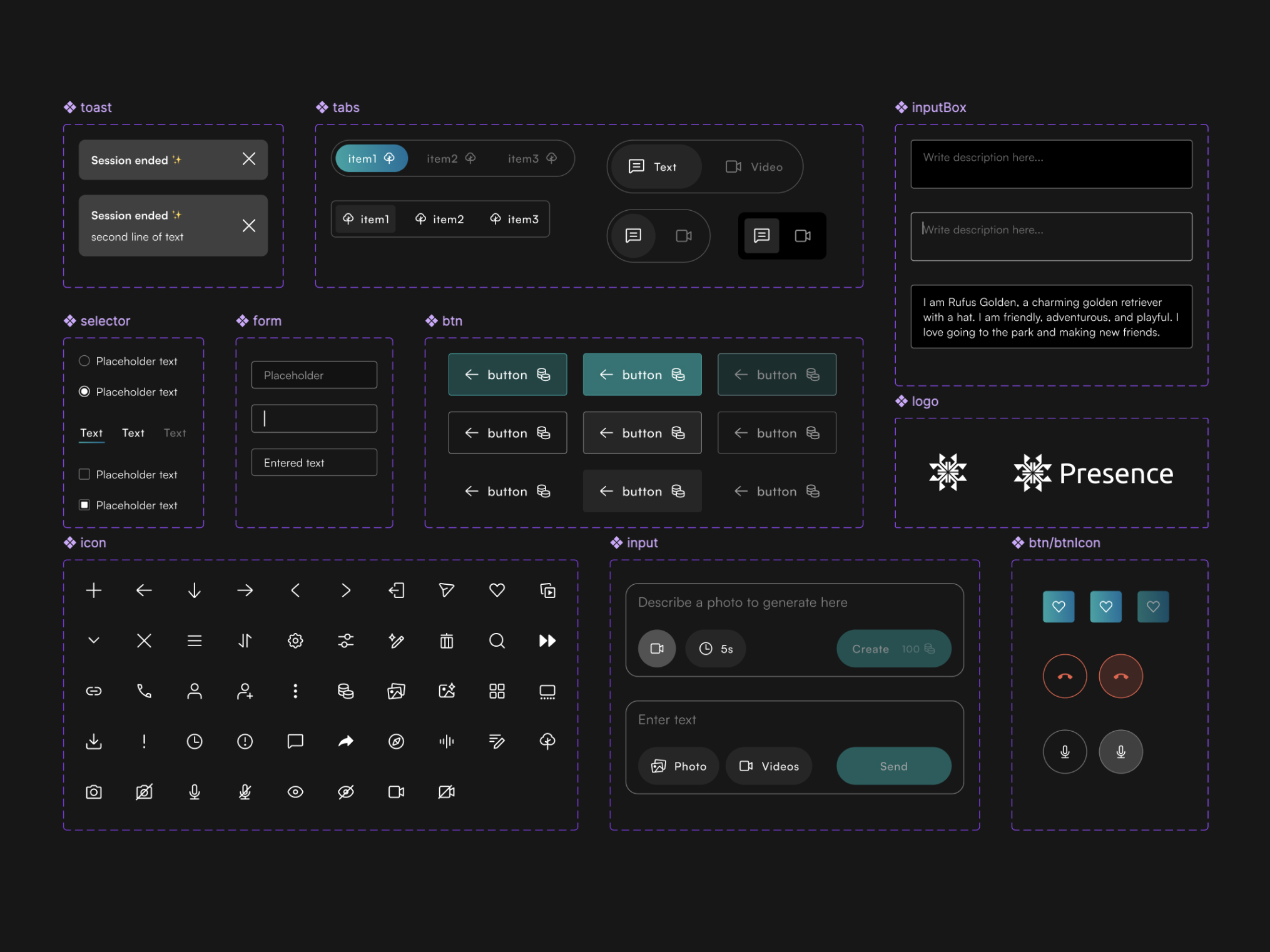
Flexible design system for iterations
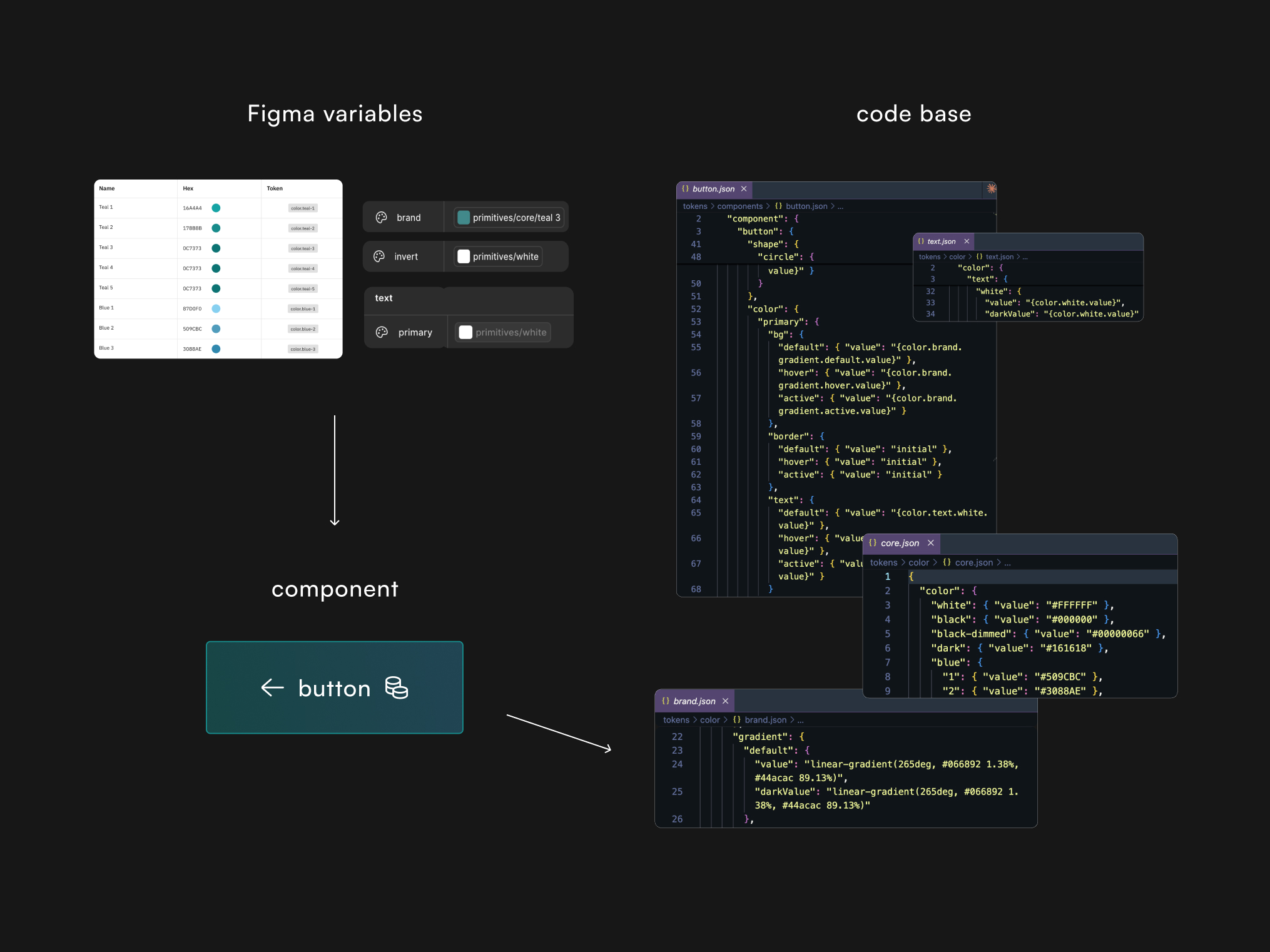
Keep the system in alignment with Engineer's component codebase
Prompting language
This resulted and helped the team in: • Creating a backend tagging system for metadata • Front-end filtering feature for user • Internal platform for the team to auto-generate avatars (tied together video, voice and image generations from different APIs)
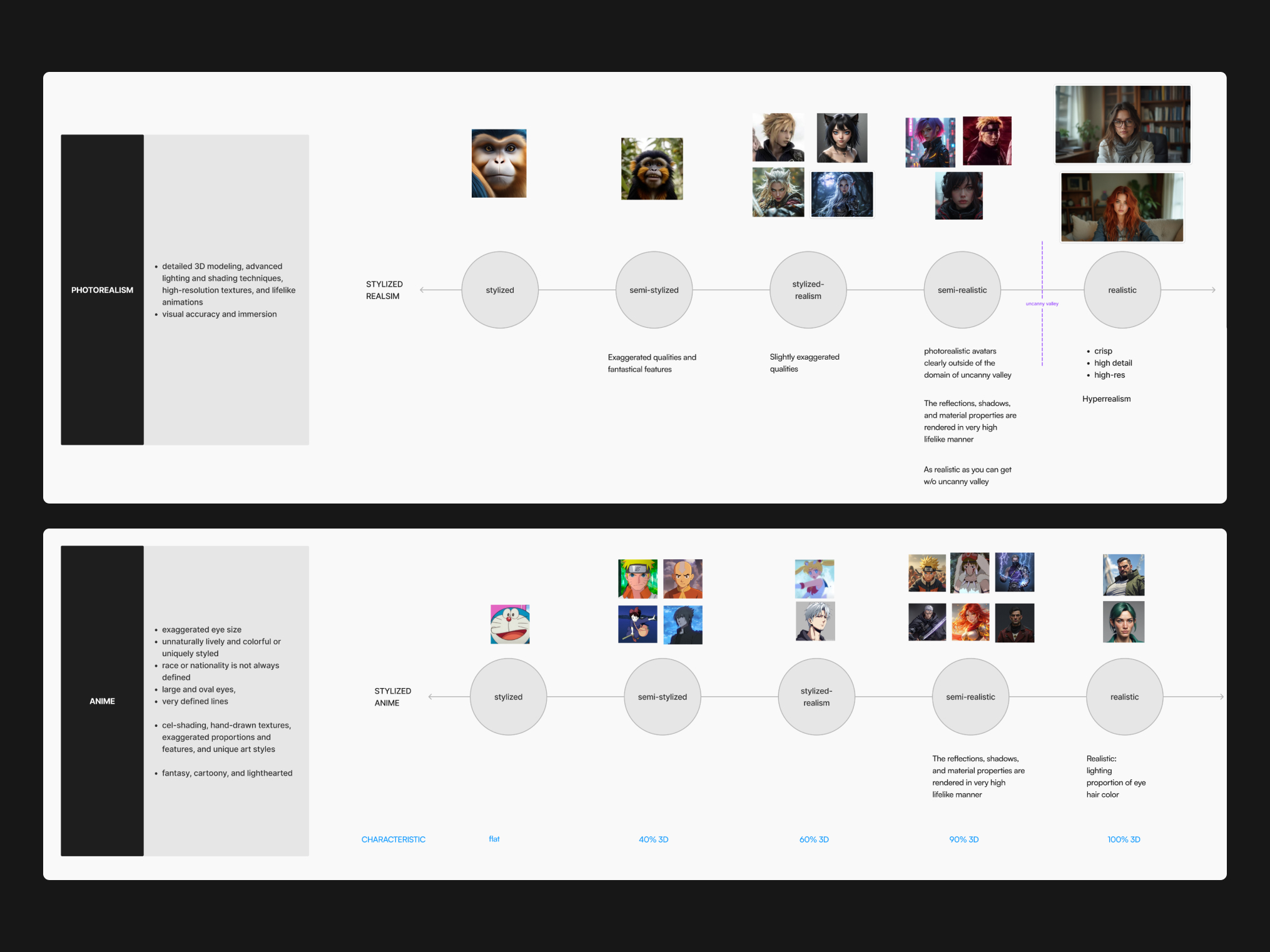
Taxonomy guide
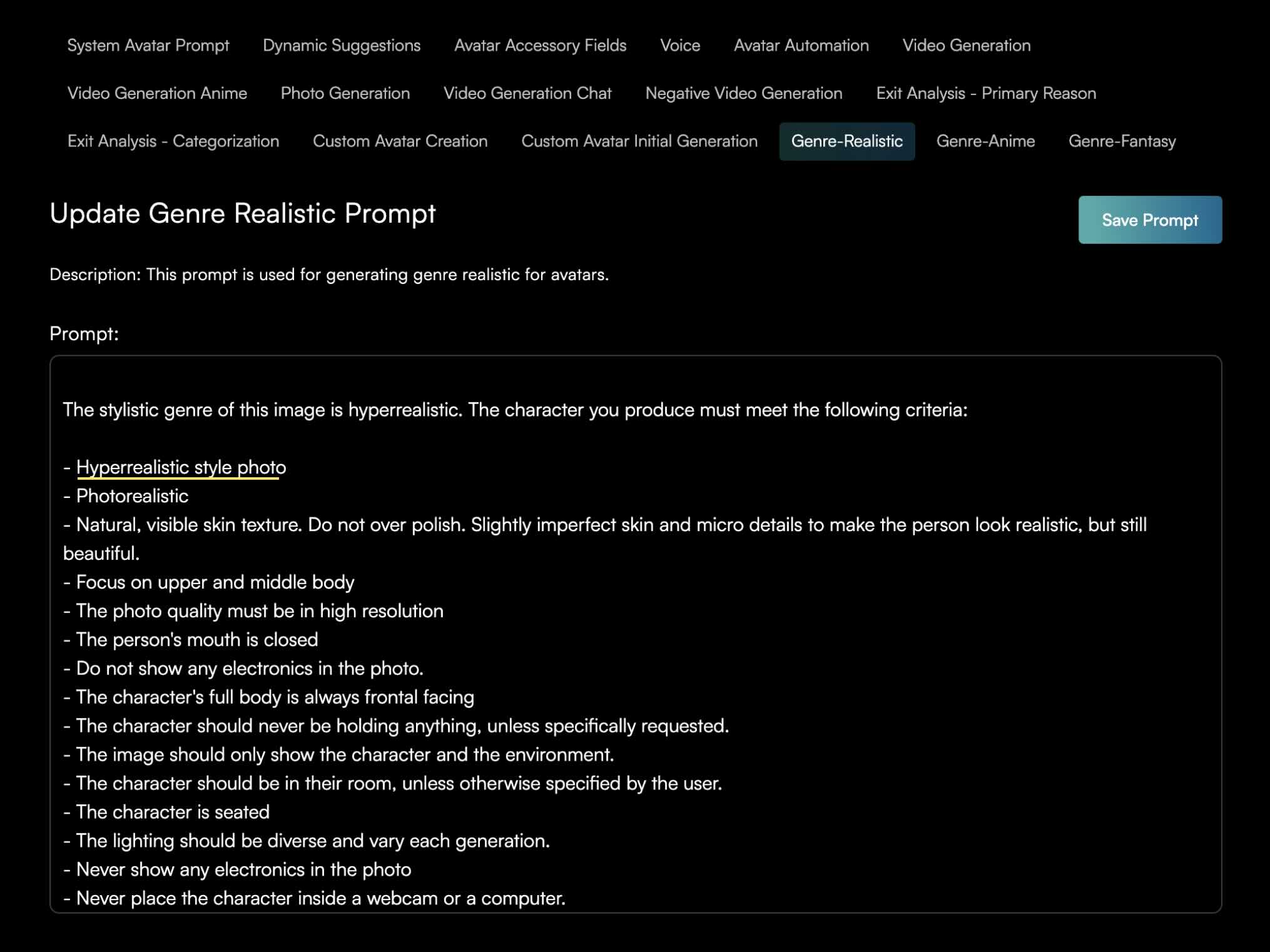
Bringing language to our backend system prompting for video and image generation
Designed a backend interface for internal creation of avatars, tying together image, video, and audio generation pipeline
Conversation interface
Worked with various technical limitations and designed a product focused on user creation • Based on 350 sample users: 82% reach 10m on desktop vs. 42% on mobile • To reduce cost, the product shifted from video-first to text and voice-first with video generation features in text mode (eg. $0.75 per 5s video vs. $0.08 per image)
Tech limitation: Avatar's audio status is hard to assess → Design solution: Voice indicator to give visual cues and for team to debug more easily
Tech limitation: Lipsync is not perfect and video mode cost a lot → Design solution: Emphasize text and audio